Audio-Visual Scene Analysis with
Self-Supervised Multisensory Features
Andrew Owens Alexei A. Efros
UC Berkeley
 |
 |
 |
|
Abstract
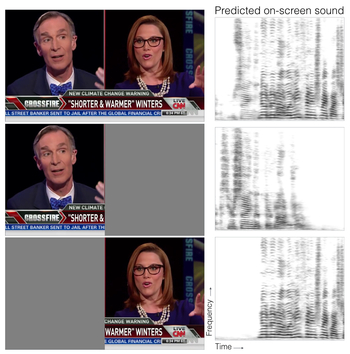
The thud of a bouncing ball, the onset of speech as lips open — when visual and audio events occur together, it suggests that there might be a common, underlying event that produced both signals. In this paper, we argue that the visual and audio components of a video signal should be modeled jointly using a fused multisensory representation. We propose to learn such a representation in a self-supervised way, by training a neural network to predict whether video frames and audio are temporally aligned. We use this learned representation for three applications: (a) sound source localization, i.e. visualizing the source of sound in a video; (b) audio-visual action recognition; and (c) on/off-screen audio source separation, e.g. removing the off-screen translator's voice from a foreign official's speech.Video
Concurrent work
Concurrently and independently from us, a number of groups have proposed closely related — and very interesting! — methods for source separation and sound localization. Here is a partial list:- Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, In So Kweon. Learning to Localize Sound Source in Visual Scenes
- Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, Michael Rubinstein. Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
- Aviv Gabbay, Asaph, Shamir, Shmuel Peleg. Visual Speech Enhancement using Noise-Invariant Training
- Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh McDermott, Antonio Torralba. The Sound of Pixels
- Relja Arandjelovic, Andrew Zisserman. Objects that Sound
- Ruohan Gao, Rogerio Feris, Kristen Grauman. Learning to Separate Object Sounds by Watching Unlabeled Video
- Triantafyllos Afouras, Joon Son Chung, Andrew Zisserman. The Conversation: Deep Audio-Visual Speech Enhancement